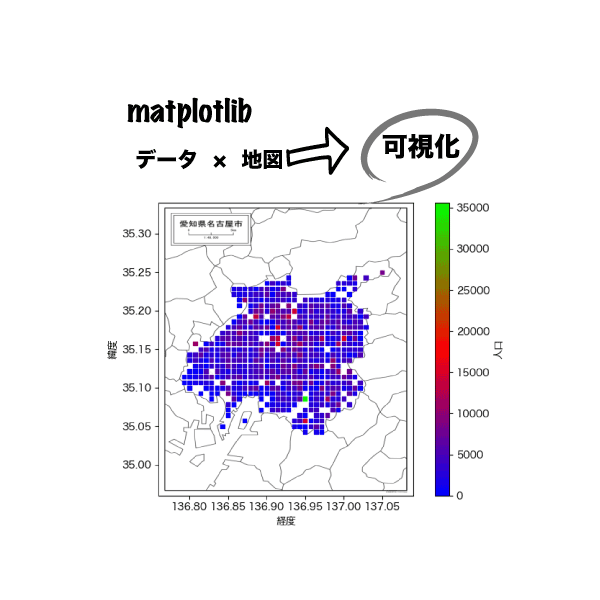
matplotlibを使って僕の地元である名古屋市の地図上に人口密度のヒートマップを作成してみました。
近年ではビッグデータを意思決定の判断材料として活用する流れが加速しています。ただ、ビッグデータをそのまま眺めても何も見えてこないので、事前にヒトの目で見てわかりやすい形に可視化する必要があります。棒グラフや円グラフ程度であればExcelで作成できても、座標上へのプロットまではできません。この部分がmatplotlibを使える人間の大きなアドバンテージになります。それでいて、GISを使って表現するよりずっとお手軽です。
と、いうことで今回は、名古屋市の地図上に人口密度のヒートマップを作成する手順を、データの入手方法も含め紹介します。こういった作業はjupyterlabでの作業が効率的です。解説もjupyterlab環境を前提にしていきます。
地図画像のダウンロード
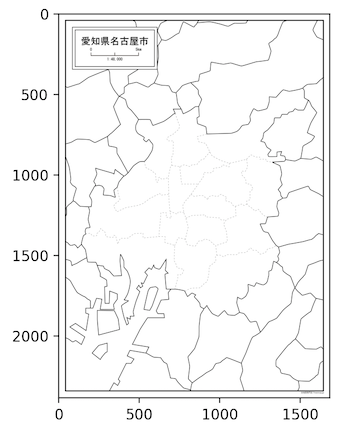
地図画像は、白地図専門店 愛知県名古屋市の白地図を無料ダウンロードから無料の白地図をダウンロードしました。Googleの画像検索で「名古屋市 地図」などで検索して見つけました。画像の利用許諾などを確認したうえで活用しましょう。
ダウンロードしたら、matplotlibで地図だけ表示してみましょう。
import matplotlib
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib ipympl
map_image = Image.open('map.png')
plt.imshow(map_image)
map_image.close()
人口データのダウンロードと観察
愛知県の人口データは名古屋市 町・丁目(大字)別、年齢(10歳階級)別公簿人口(全市・区別)からダウンロードしました。Googleで「名古屋市 人口 データ ダウンロード」といったキーワードで検索して見つけました。
この記事を書いている時点での最新データは令和3年4月のデータでした。nagoya_population.xlsxなど適当な名前をつけて保存して、ExcelやMacのNumbersで開いてデータの中身を観察してみましょう。データサイエンスでは、データを活用する前に観察をして、手元にあるデータがどういった性質のものであるのかを正確に把握する作業が地味に大切です。
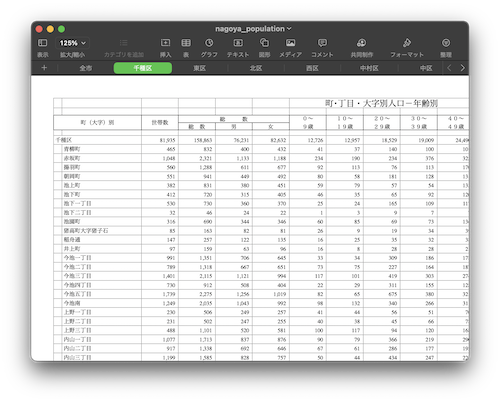
確認した結果、次のことがわかりました。
- 最初のシートは名古屋市全体の総括(よってこのシートの情報は不要)
- 各区の情報はシート分けしてある
- 使えるデータは0インデックスの6行目から
- 大字列(位置情報)と総数列(人口情報)の列が活用できそう
座標データをダウンロード
nagoya_population.xlsxのデータは住所の大字(おおあざ)単位でしたが、地図上にプロットするためには座標情報にマッピングする必要があります。座標データは国土交通省の街区レベル位置参照情報からダウンロードできます。Googleで「日本 座標 コード ダウンロード」といったキーワードで検索して見つけました。
ダウンロードは「都道府県単位」→「愛知」チェック→「街区レベルのみ」と選ぶと大字単位の住所と座標の関連付けに使えそうなデータがダウンロードできました。ここでダウンロードしたファイルは文字コードがsjisなので、utf-8に変換してgeo.csvといった名前にでも変更して保存しましょう。先ほどの人口情報と同様に、このファイルの内容も観察します。こちらはcsv形式なのでjupyterlabから直接閲覧できました。
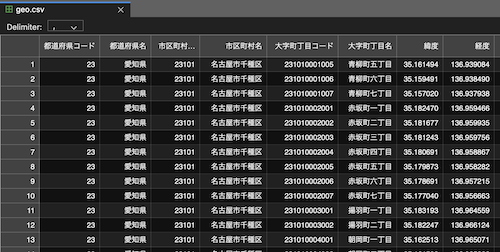
確認した結果、次のことが見えてきました。
- 地図上にプロットするための「緯度」と「経度」の情報がちゃんとある
- 「市区町村名」と「大字町丁目コード」をキーにしてジョインできそう
人口データを地図上に可視化
地図画像、人口情報、座標情報と必要な材料がそろったので、matplotlib上に可視化していきましょう。各区ごとにシート分けしてあった人口情報を読み込みます。pandasのread_excel()関数のsheet_name引数に読み込みたいシート名を指定すると、シート名をキーにしたdictとしていっきに読み込むことができます。
import pandas as pd
segs = ['千種区', '東区', '北区', '西区', '中村区', '中区', '昭和区', '瑞穂区',
'熱田区', '中川区', '港区', '南区', '守山区', '緑区', '名東区', '天白区']
df_dict = pd.read_excel('nagoya_population.xlsx',
sheet_name=segs,
skiprows=[0, 1, 2, 4, 5],
usecols=[1, 3],
names=('大字', '人口'))
df_dict[segs[0]]

区ごとに分かれているままでは都合が悪いので、1つのデータフレームに結合します。
# dictのキー名から区の情報を作成
for seg in segs:
df = df_dict[seg]
df['区'] = f'名古屋市{seg}'
# 一番最初のデータフレームに以降のデータフレームを結合
dfs = list(df_dict.values())
popu = dfs[0].append(dfs[1:])
popu
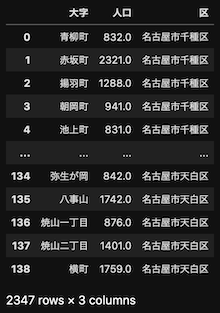
緑区のシートの最後だけ「※ 鳴海町は区域が広いため、字別のデータも集計して掲載しています」というテキスト行があったせいでNaNになっていました。
popu[pd.isna(popu['大字'])]

このNaNデータを取り除きます。
popu.dropna(inplace=True)
popu[pd.isna(popu['大字'])]

人口情報は使える形になったので、続いて座標情報を読み込みます。名古屋市以外のデータも含まれているので排除して、ジョインするためのフィールド名を変更しておきます。
geo = pd.read_csv('geo.csv')
geo = geo[['市区町村名', '大字町丁目名', '緯度', '経度']]
geo = geo[geo['市区町村名'].str.startswith('名古屋市')]
# ジョインのためにフィールド名を合わせておく
geo.rename(columns={'市区町村名': '区', '大字町丁目名': '大字'}, inplace=True)
geo
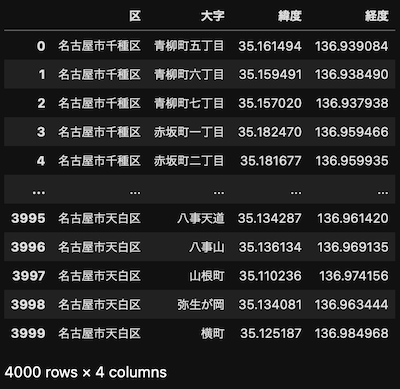
このまま「区」と「大字」でジョインしたいところですが、人口情報と座標情報の両者の間には、「大字」の粒度が微妙に一致しないデータがそこそこあります。かたや「青柳町」、かたや「青柳町一丁目」や「青柳町二丁目」、といった感じです。
このままではジョインできないので、「〇〇町」は全て「〇〇」に、「〇〇一丁目」などは全て「〇〇」など、末尾の情報を取り除くことで名前を合わせました。(かなり強引な方法です)
import re
sec_regex = re.compile(r'町?([一二三四五六七八九十]丁目)?$')
for df in (geo, popu):
df['大字'] = df['大字'].apply(lambda v: sec_regex.sub('', v))
これで、「大字」の名前も一致してジョインできるようになったので、やっとこさジョインです。
# 人口情報は合計
popu = popu.groupby(['区', '大字']).sum()
# 座標情報は平均
geo = geo.groupby(['区', '大字']).mean()
joined = geo.join(popu)
joined
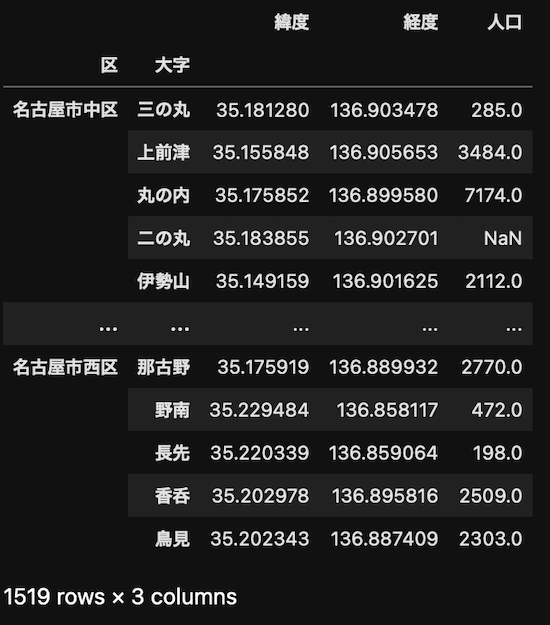
ジョインできていていい感じになりました。しかし、二の丸のデータがNaNになっています。1519件中59件がこの状態になっていますが、この辺りを解決しようとするとデータセットに対しての加工ではなくデータセットへの情報追加で何とかしなければいけない部分になってしまいます。今回はmatplotlibで可視化することそのものが目的なので、このまま進めることにします。
ということで、ここから地図上にプロットしていきます。大字ごとに1プロットするのではなく、タイル状にプロットしたいので、座標の小数点を丸めてグループ化し、同じグループになった人口同士の和を求めます。
joined = joined.round({'経度': 2, '緯度': 2})
joined = joined.groupby(['経度', '緯度']).sum()
joined = joined.reset_index()
len(joined) # => 331タイルにグループ化された
331タイルにグループ化することができたので、matplotlibを使ってプロットしていきます。経度情報をx、緯度情報をy、人口情報をcolorの引数に使うことで、位置と色から視覚的に見えるタイルプロットが可能になります。
import matplotlib
import matplotlib.pyplot as plt
%matplotlib ipympl
# MacOSで使用可能なフォント。Windowsだと異なるかも。
matplotlib.rcParams['font.family'] = 'Hiragino Sans'
fig, ax = plt.subplots()
joined.plot.scatter('経度', '緯度', s=25, cmap='brg', colorbar=True,
c='人口', alpha=1, marker='s', ax=ax)
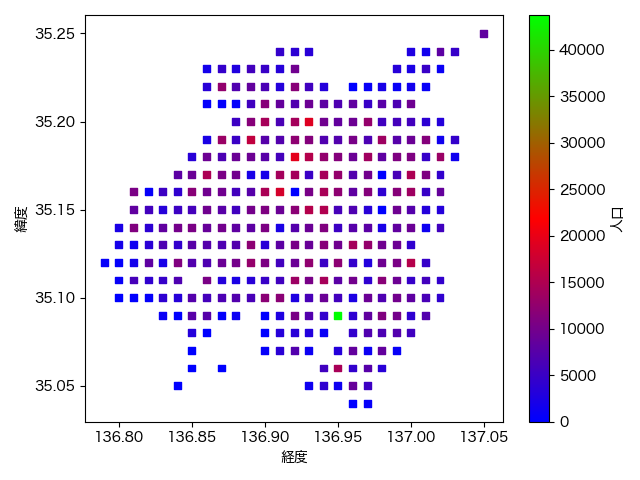
marker='s'(square)として四角図形を表示していますが、これは結構軽はずみな思いつきなので、もっと他に良い方法があるかもしれません。とはいえ意思決定に使えそうな品質は満たしているのでヨシとします。あとはここに地図情報を重ねておわりです。
from PIL import Image
with Image.open('map.png') as im:
# extentで地図の端の座標を設定。微調整が必要になる部分。
ax.imshow(im, extent=(136.76, 137.09, 34.96, 35.34))
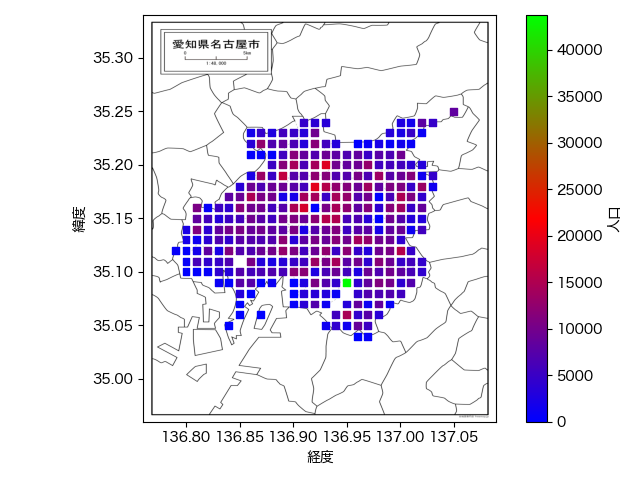
ax.imshow()関数を呼び出すときにextentパラメータに地図の端の座標を指定して、プロットしたデータ上に地図がうまく重なるようにするのがコツです。地図の上下左右の座標がわからない場合は少しずつ調整して適正値を見つける必要があって、これが少し面倒な作業です。そんなこんなで、意思決定に使える品質を満たしたプロットが完成しました。
答え合わせ
可視化した情報が間違っていると、それを元にした意思決定も間違ったものになってしまいます。だからこそ情報を可視化したら、それが現実に則したものであるかどうかを慎重に確認する必要があります。実は名古屋市の人口密度のヒートマップは、Googleで「名古屋市 人口 地図」として画像検索すると見つけることができます。今回は名古屋市が公開しているメッシュ統計(平成17年国勢調査)を答え合わせに使いました。
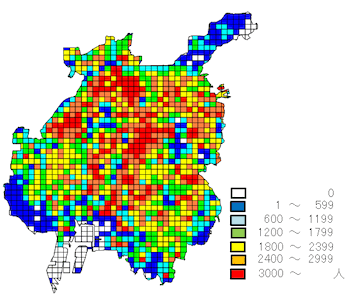
情報が少し古いですが、今回作成した人口密度ヒートマップと概ね同じ傾向があるので、正しく可視化できていると考えてよさそうです。
あとがき
こんな感じで、人口密度を地図上に可視化してみました。人口密度情報なら探せば見つかりますが、自分でプロットして作成する強みとしては、例えばこの人口密度情報に飲食店件数データを合わせて対人口比の店舗数ヒートマップ(いわゆる激戦区ヒートマップ)を作って出店戦略に活用する…など自由な応用ができる点だと思います。
自由度の例として、例えばタイルをもう少し細かく表示したいと考えた場合なども丸め計算を少し変更すれば対応できたりします。今回のような大字単位の人口集計情報だと細分化しすぎるとどうしてもタイルの欠損が出てくるので、入手できたデータとの兼ね合いで調整しつつにはなりますけれど。
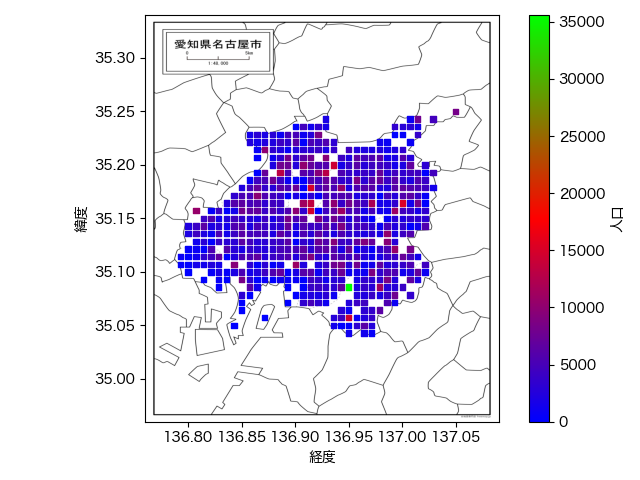
こんな感じで、今回のmatplotlibを使った地図上へのデータの可視化は成功したのでした。