YOLOv8を使い始めるにあたって知っておきたい情報をまとめました。
なぜYOLOv7ではなくYOLOv8を使うのか?からはじまって、インストール、yoloコマンドの使い方、Google Colaboratoryで使う方法、オリジナルのモデルを作る方法、などまで解説しています。
YOLOv8とYOLOv7の違い
2023年4月時点で最新のYOLOといえば、YOLOv7とYOLOv8です。
YOLOv7もYOLOv8も物体検出できる点、PyTorchを使っている点、については同じです。
どっちを使おうか迷う人も多いと思います。ということでこの2つのYOLOについて、少し比較情報を共有しておきます。
リリースタイミング
YOLOv7が2022年7月にリリースされたのに対して、YOLOv8は2023年1月にリリースされました。つまりバージョン名が表すように、YOLOv8のほうが半年ほど若く、最新バージョンだといえます。
とはいえ、YOLOv8がYOLOv7の純粋な進化系なのかというと、それは違います。それぞれ異なる開発者が開発して、YOLOの名前を使って順番にYOLOv7とかYOLOv8とか名前をつけてリリースしているに過ぎないからです。
YOLOv8の開発者であるUltralytics社は、以前にYOLOv5をリリースしていています。そういう考えでは、YOLOv8はYOLOv5を進化させたものであると言えます。
インストール方法や使い方
YOLOv7の使い方
YOLOv7はPyTorchのDockerコンテナを立ち上げて、そこにいくつかパッケージをインストールする方法が推奨されています。
# create the docker container, you can change the share memory size if you have more.
nvidia-docker run --name yolov7 -it -v your_coco_path/:/coco/ -v your_code_path/:/yolov7 --shm-size=64g nvcr.io/nvidia/pytorch:21.08-py3
# apt install required packages
apt update
apt install -y zip htop screen libgl1-mesa-glx
# pip install required packages
pip install seaborn thop
# go to code folder
cd /yolov7
ちなみに僕はMacユーザーなのですが、Macで使う場合はnvidia-dockerもnvcr.io/nvidia/pytorch:21.08-py3コンテナイメージも使えないなど、色々と工夫してCPUだけで動作させるようにする必要があって、けっこう苦労しました。
どれほど苦労するかについてはMacでYOLOv7を使うの記事でまとめています。
YOLOv8の使い方
YOLOv8はpythonのパッケージをインストールするだけで使えるようになります。
pip install ultralytics
(YOLOv8のパッケージ名にultralyticsという会社名そのものをつけてしまっているところが若干主張が激しい気もしなくもない)
主張満々Ultralyticsパッケージをインストールするとyoloコマンドが使えるようになり、すぐに物体検出することができるようになります。
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
物体検出ではなくセグメンテーションしたい場合は、yolov8n.ptではなくyolov8n-seg.ptを使うだけです。
yolo predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg'
後述のyoloコマンドの章で踏み込んで説明します。
開発者
YOLOv7の開発者
YOLOv7の主要開発者の1人はAlexey Bochkovskiyさんです。
Alexey BochkovskiyさんはYOLOv4も開発している方です。
YOLOv7は他のトランスフォーマーベースのモデルと比べ正解率10倍速い。MSCOCOデータセットに対しての物体検出とセグメンテーション性能は同等だ。既存のモデルを改善するより最善のモデルを作ろう。
Alexey BochkovskiyさんのTwitterでのフォロワー数は2776人です。
GitHubのリポジトリ管理者はKin-Yiu Wongさんで、香港(つまり中国)にある大学の助教です。Google Scholarではこの方が書いた論文が多数確認できます。
ただ、中国の裏事情を語るYouTubeチャンネル妙佛 DEEP MAXで紹介されている、中国のスパイ活動に関する動画では、中国政府が一般の中国人に働きかけて企業機密などを盗み出させるというような内容が紹介されていて、中国人がリポジトリの管理者である場合、リポジトリ内に悪意あるコードを埋め込む可能性などについて、不安が拭えない…。
いかん、いつもの考え過ぎる悪いクセがでちまいました。
YOLOv8の開発者
Glenn Jocherさん
YOLOv8の開発者はUltralytics社ですが、その創設者はGlenn Jocherさんです。
YOLOv8はここだよ!数ヶ月にわたるハードワークの末、我々はついに次なる大ブームを立ち上げた。
Ultralyticsチームを誇りに思う!!
Glenn JocherさんのTwitterでのフォロワー数は216人です。
YOLOv4とYOLOv7の主要開発者であるAlexey Bochkovskiyさんのフォロワー数と比べるとかなり少ないですね。。
でも彼が興したUltralytics社のフォロワー数は、1267人です。うーん、企業としては少ない気がします。
Ultralytics社大丈夫か!?と思ってWebサイトをさらっと見た結果、マトモな会社判定を下すことができました。
- 2014年設立
- YOLOv5とYOLOv8を作成
- AIをシンプルなものにすることで誰もが簡単に使えるようにすることが目標
- スマホカメラでYOLOv5の物体検出するアプリVision AIを提供
- 物体検出モデルを簡単に作成するWebインターフェイスUltralytics HUBを提供
- Vision AIとUltralytics HUBはYOLOv8に対応中
まだ課金サービスがリリースできていない新興企業ということで、安定した活動については不安が残るかもしれません。
YOLOv8のほうがよさげ
- リリースタイミング→YOLOv8のほうが新しい
- インストール→YOLOv8のほうが簡単
- 開発者→YOLOv8は中国絡んなくて安心
YOLOv7とYOLOv8を比較して考えたとき、僕の中で、使うならYOLOv8かなって結論になりました。
皆さんはどう思われたでしょうか?
インストール
インストールはめっちゃシンプルです。
Pythonが使える環境なら、pipでインストールできます。
pip install ultralytics
yoloコマンド
ultralyticsをインストールすると、yoloコマンドが使えるようになります。
物体検出をしてみましょう。YOLOv8のGitHubのページで紹介されている検出コマンドのサンプルです。
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
コマンドを実行すると、検出結果がruns/detect/predict/bus.jpgに作成されます。
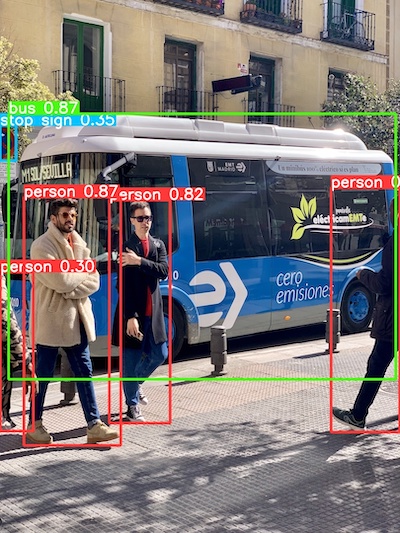
使用するモデルをyolov8n.ptからyolov8n-seg.ptに変更すると、セグメンテーションができます。
yolo predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg'

これまで使っていたyolov8n.ptやyolov8n-seg.ptの「n」はモデルのサイズを表しています。
x > l > m > s > n
xが最も大きいモデルで、nが最も小さいモデルです。
大きいモデルは検出にパワーが必要になるものの、検出精度が高くなります。
試しにxサイズのモデルで検出をかけてみます。
yolo predict model=yolov8x.pt source='https://ultralytics.com/images/bus.jpg'

見落としがちな右上にある自転車も、ちゃんと検出できました。
さらにポーズ検出も試してみます。セグメンテーションと同様に、yolov8x.ptの代わりにyolov8x-pose.ptを使います。
yolo predict model=yolov8x-pose.pt source='https://ultralytics.com/images/bus.jpg'

首から上が緑、腕が青、体がパープル、足がオレンジ色で、それぞれポーズが検出できています。
なぜか右上の自転車を検出しなくなったところはツッコミたいところです。
ちなみに、yolov8n.pt、yolov8n-seg.pt、yolov8n-pose.ptなどについての情報は、YOLOv8 Modelsにあります。
Colaboratoryで使う
ケンヂまるの環境はMacなので、GPUを活用できません。
なので、Google Colaboratoryを利用します。Google Colaboratoryでは、GoogleインフラのGPUパワーを無料で使うことができます。商用での利用も同じく無料なので、企業活動としても気軽に使えます。
てことで、このColaboratory上でYOLOv8を動かしてみます。
Colaboratoryファイルを作成する
まず新しいColaboratoryファイルを作成します。自分のGoogleドライブを開いて、「+新規」をクリックします。
「その他」→「Google Colaboratory」と選択すると、Colaboratoryファイルが作成されます。Google Colaboratoryを使ったことがない人は、選択肢に出てこないと思うので、その場合は「+ アプリを追加」を選択します。
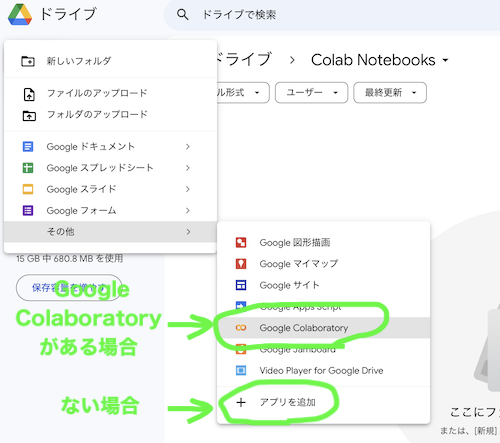
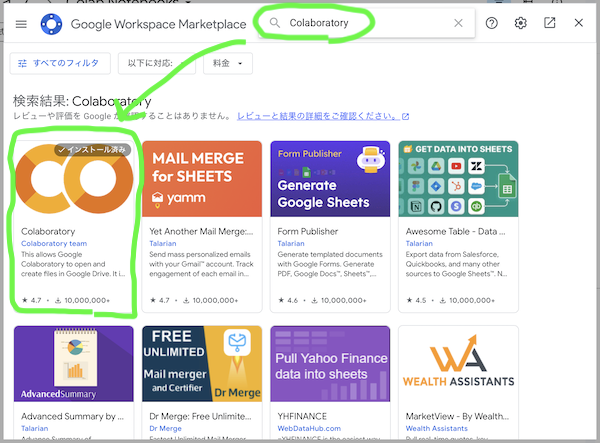
Google Workspace Marketplaceのダイアログで「Colaboratory」と入力して検索し、表示されたColaboratoryをインストールします。(画像は僕の環境のスクショなので、「✔️インストール済み」ってなってます)
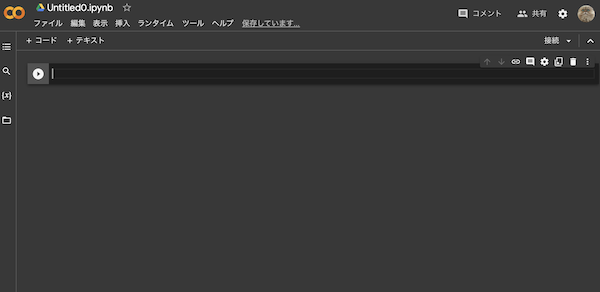
Google Colaboratoryを作成すると、Jupyter Notebookのような画面に切り替わります。使い方もJupyter Notebookとほぼ同じです。
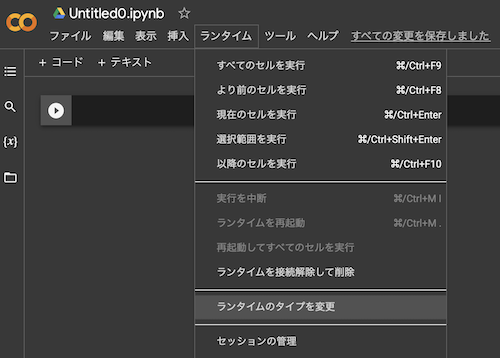
GPUを有効にする
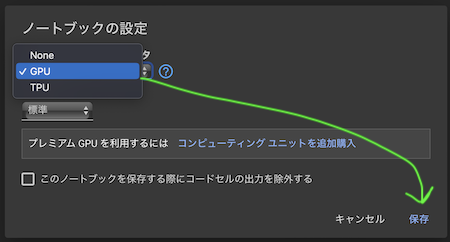
ColaboratoryはデフォルトではGPUがオフになっているので、「ランタイム」→「ランタイムのタイプを変更」の順に選択し、ダイアログで「GPU」を選択します。
YOLOv8をインストールする
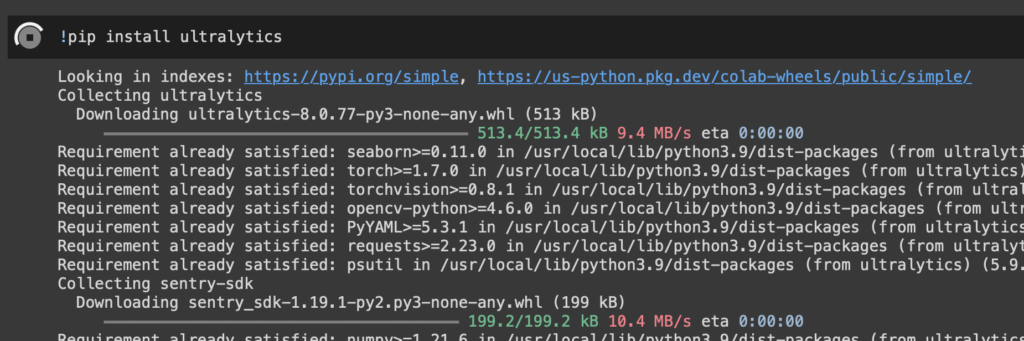
YOLOv8のインストールは、前述したようにpip install ultralyticsコマンド一発で終わります。
Jupyter Notebook上からPythonプログラムではなくターミナル用コマンドを実行する場合は最初に"!"を付ける必要があるので、実際は!pip install ultralyticsと入力してから[Shift]+[Enter]です。
物体検出実行
GPUのパワーを実感できる重たい処理を実行してみましょう。
Ultralytics > Quickstartで紹介されている、YouTubeの動画に対してセグメンテーション処理をかけるサンプルを実行してみます。
ただし、性能差がわかりやすいように、モデルはyolov8n-seg.ptではなくてよりパワーを必要とするyolov8x-seg.ptを使い、imgsz=320も指定しないようにしましょう。(imgszを指定しない場合yolov8x-seg.ptのデフォルトのイメージサイズ640になる)
!yolo predict model=yolov8x-seg.pt source='https://youtu.be/Zgi9g1ksQHc'
セグメンテーションの処理が始まります。
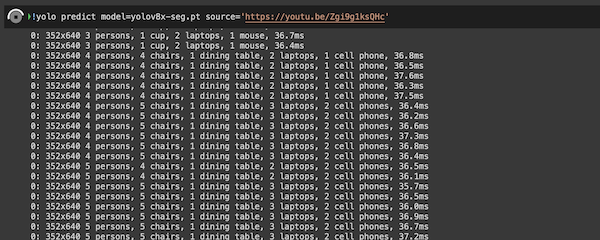
1フレームの処理時間が37ms程度なので、27FPSほどの処理性能が出ています。
これと同じ処理をMacBook Pro M1 Maxで実行すると、1フレームあたりの処理時間が270ms程度、つまり3FPSでした。
GPUで実行すると9倍速いみたいです。
結果を確認する
左側の📁アイコンをクリックするとファイルが表示されます。
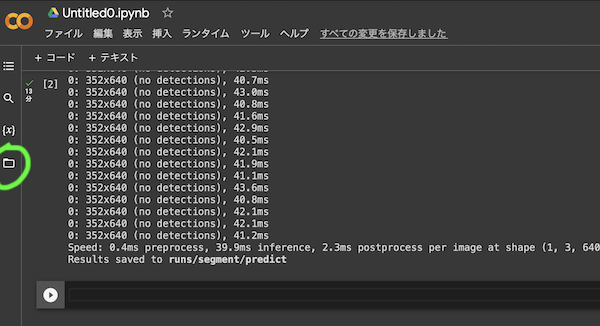
runs/segment/predictフォルダの下に検出処理済みの動画ファイルが作成されているので、ダウンロードして確認してみましょう。
ダウンロード速度は遅めですね。。時間かかりました。
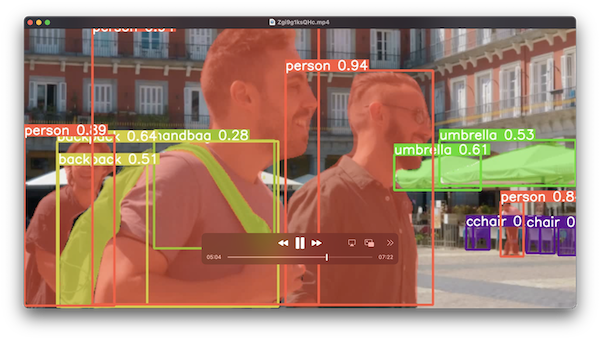
ダウンロードした動画を再生してみると、すべてのフレームにセグメンテーションの結果が反映されていました。この処理を27FPSでできた…だと!?
Pythonで実行
ColaboratoryはそもそもPython実行環境なので、Pythonプログラムで実行してみます。
from ultralytics import YOLO
# モデルの関数作成
model = YOLO('yolov8n.pt')
# 検出して結果を取得(結果分の要素が含まれた配列で返る)
results = model('https://ultralytics.com/images/bus.jpg')
# 1画像しか渡していないので結果は1つ
result = results[0]
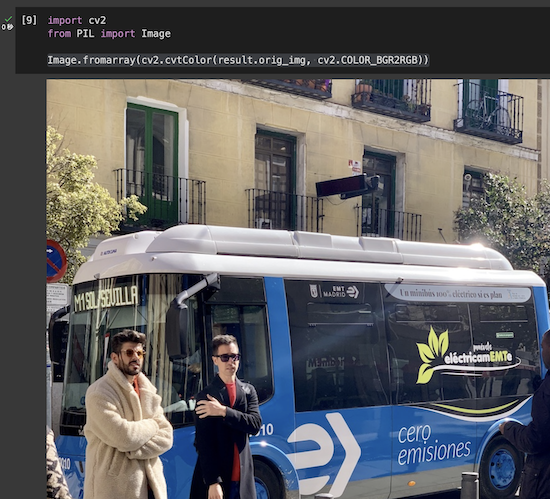
result変数に格納されている結果はultralytics.yolo.engine.results.Resultsタイプなので、orig_imgプロパティにアクセスして検出対象の画像(検出処理前)を取得・表示してみます。
検出対象の画像(検出処理前)を表示:
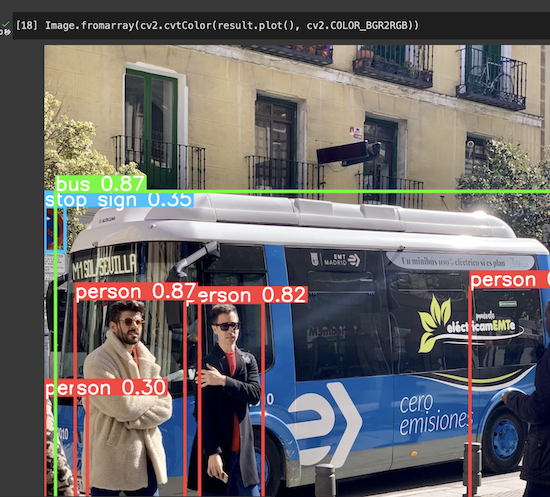
次に、plot()メソッドを呼び出して、バウンディングボックスを描画した画像を取得・表示してみます。
バウンディングボックスを描画した画像を表示:
トレーニング
使うだけじゃなくてトレーニングもしてみます。キャンプで使われる焚き火台を見分けるモデルを作ってみました。
最近ではWeb上で一通りの作業が完結するようなWebアプリも多く提供されていますが、ここではローカル環境で完結する方法を試しました。
完全に解説するとけっこう細かくなってしまうので、イメージが伝わる程度の内容レベルで共有しておきます。
データを収集
トレーニングするためには、まず画像を収集します。
以前個人的に焚き火台の画像を収集していたのを思い出したので、その画像を流用しました。
動作検証が目的なので、あまり気合の入ったモデルは作りません。ブッシュクラフト社のウルトラライトファイヤースタンドと、ロゴス社のザ・カマドの2種類の焚き火台に絞って、さらに画像も10枚程度にしておきます。
ブッシュクラフト社のウルトラライトファイヤースタンド ロゴス ザ カマドデータにアノテーションをつける
集めた画像に対してアノテーションをつけていきます。個人的にはMacの環境ならReactLabelが直感的に使えてオススメです。
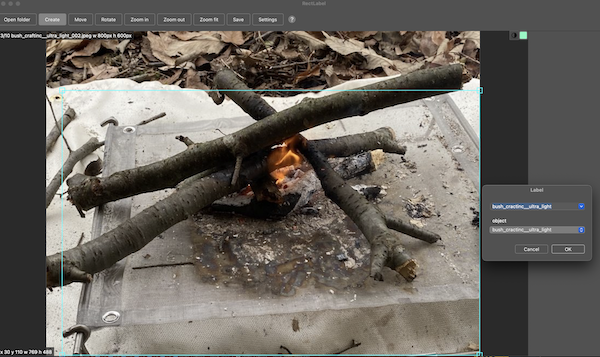
画像が入ったフォルダを開くと画像が表示されるので、それぞれ焚き火台を囲い、名前を入力していきます。
ウルトラライトファイヤースタンド:
ザ・カマド:
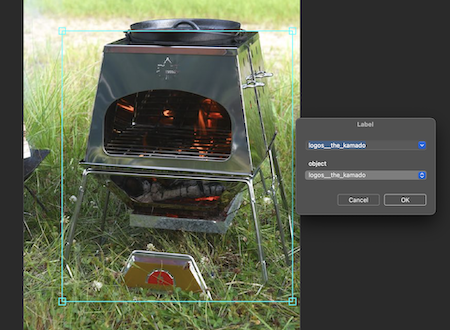
囲って名前をつけると、画像ファイルと同じ名前の.txtファイルが作成されていきます。これがアノテーションデータです。

アノテーションデータの内容は、物体IDと、囲った四角形の座標です。1つの画像の中で複数の物体があれば、その物体の数だけ行数が増えます。
0 0.500000 0.564062 1.000000 0.863542
今回の物体IDは、ウルトラライトファイヤースタンドが0で、ザ・カマドが1です。
train/val/testに分ける
アノテーションデータを作成したら、ReactLabelのExport機能を使って、トレーニング用データ(train)、検証用データ(val)、テスト用データ(test)に分けます。
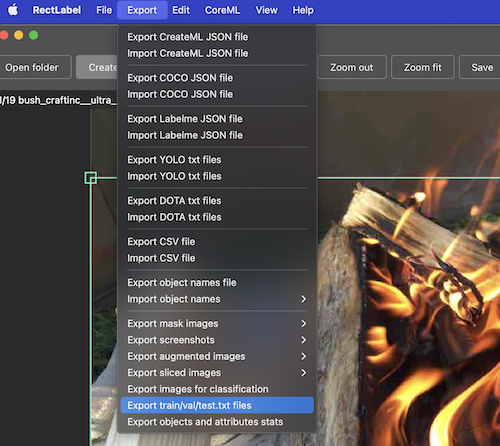
といってもRectLabelがやってくれるのは、それぞれの画像パスが書かれたテキストを出してくれるだけです。

train.txtの内容:
/Users/jimaru/jupyter/yolov8/dataset/bush_craftinc__ultra_light/bush_craftinc__ultra_light_000.jpg
/Users/jimaru/jupyter/yolov8/dataset/bush_craftinc__ultra_light/bush_craftinc__ultra_light_001.jpg
/Users/jimaru/jupyter/yolov8/dataset/bush_craftinc__ultra_light/bush_craftinc__ultra_light_002.jpeg
/Users/jimaru/jupyter/yolov8/dataset/bush_craftinc__ultra_light/bush_craftinc__ultra_light_006.jpg
/Users/jimaru/jupyter/yolov8/dataset/bush_craftinc__ultra_light/bush_craftinc__ultra_light_008.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_000.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_001.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_003.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_004.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_005.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_006.jpg
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_007.JPG
/Users/jimaru/jupyter/yolov8/dataset/logos__the_kamado/logos__the_kamado_009.jpg
こんな感じでtrain.txt、val.txt、test.txtにファイルパスを振り分けてくれるんですけど、これだけじゃトレーニングの準備としては不十分で、trainフォルダ、valフォルダ、testフォルダに画像とアノテーションデータを移動させる必要があります。
具体的にいうと、
dataset
|- bush_craftinc__ultra_light
|- bush_craftinc__ultra_light_000.jpg
|- bush_craftinc__ultra_light_000.txt
|- ...
|- logos__the_kamado
|- logos__the_kamado_000.jpg
|- logos__the_kamado_000.txt
|- ...
となっているところから、
dataset
|- images
|- train
|- bush_craftinc__ultra_light_000.jpg
|- bush_craftinc__ultra_light_000.txt
|- val
同様に画像とテキスト
|- test
同様に画像とテキスト
|- labels
|- train
同様に画像とテキスト
|- val
同様に画像とテキスト
|- test
同様に画像とテキスト
こんな感じに振り分けます。
これをやってくれるツールの存在を知らないので、Pythonプログラムを書いて代用しました。
from pathlib import Path
import shutil
WORK_DIR = Path('/Users/jimaru/jupyter/yolov8/dataset')
# 画像用フォルダ
images_dir = WORK_DIR / 'images'
# アノテーション用フォルダ
labels_dir = WORK_DIR / 'labels'
TYPES = ['train', 'val', 'test']
# dataset/images作成
images_dir.mkdir(exist_ok=True)
# dataset/labels作成
labels_dir.mkdir(exist_ok=True)
# train, val, testごとに画像とアノテーションを振り分けていく
for type in TYPES:
curr_image_dir = images_dir / type
curr_label_dir = labels_dir / type
curr_image_dir.mkdir(exist_ok=True)
curr_label_dir.mkdir(exist_ok=True)
type_files = (WORK_DIR / type).with_suffix('.txt')
for f in type_files.read_text().split():
src = Path(f)
img_dest = curr_image_dir / src.name
shutil.copy(src, img_dest)
label_dest = (curr_label_dir / src.name).with_suffix('.txt')
shutil.copy(src.with_suffix('.txt'), label_dest)
実行すると、train.txt、val.txt、test.txtの内容をもとに、こんな感じで振り分けられた状態になります。(labelsのほうには対になる.txtファイルが入っている)
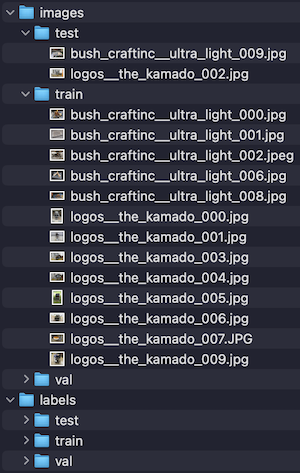
ちなみに自分でプログラム書かなくてもいい方法知ってる方いましたら、コメントで教えて下さいお待ちしてます🙇♂️
fire-pit.yamlを作成
データセットの仕上げに、トレーニング時にyoloに指定するためのファイルを作ります。
# /Users/jimaru/jupyter/yolov8/fire-pit.yaml
# 絶対パスで書くことを勧める
path: /Users/jimaru/jupyter/yolov8/dataset
train: images/train
val: images/val
test: images/test
names:
0: bush_craftinc__ultra_light
1: logos__the_kamado
YOLOv8のリポジトリに用意されているcoco8.yamlを参考にしてなんとか作りました。
path:は絶対パスで指定したほうが不幸にならずに済みます。
train:、val:、test:はなんとなく想像つくと思いますが、path:で指定されたdatasetフォルダからの相対パスです。
names:は、アノテーションファイルの物体IDと矛盾しないように注意します。
トレーニング
ここまでの作業で、fire-pit.yamlとdatasetフォルダ、その中にimagesフォルダとlabelsフォルダ、が作られた状態になりました。
work-dir
|- fire-pit.yaml
|- dataset
|- images
|- labels
これでようやく、yoloコマンドにfire-pit.yamlを指定してトレーニングできます。
yolo train data=fire-pit.yaml model=yolov8n.pt epochs=10
このコマンドを実行するとトレーニングが始まります。
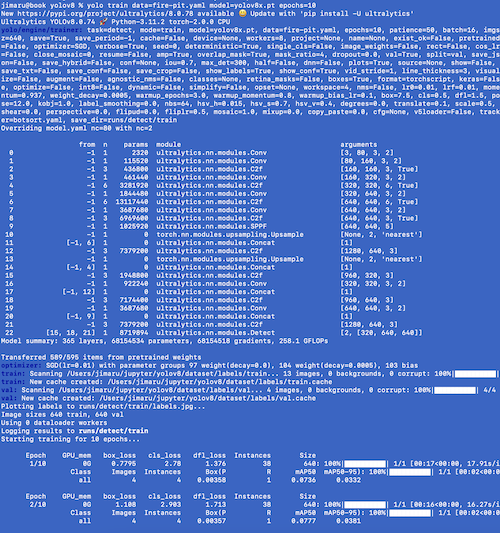
yoloコマンドへのデータの指定は、先ほど作成したfire-pit.yamlの指定だけでよくて、fire-pit.yamlの内容をもとにimagesフォルダやlabelsフォルダの情報を収集しにいくようです。
速度より精度を優先したモデルを作りたい場合はyolov8n.ptじゃなくてyolov8x.ptを指定したり、epochsにより大きな数を指定したりできます。
トレーニングが終わると、モデルがruns/detect/train/weights/best.ptに作成されます。
焚き火台を検出してみる
runs/detect/train/weights/best.ptを使って焚き火台を検出してみます。
yolo predict model=runs/detect/train/weights/best.pt source=dataset/images/val/logos__the_kamado_008.JPG
検出された画像はyoloコマンドの説明で前述した通り、runs/detect/predictに出力されます。

confidence=0.45と自身なさすぎな感じがするけど、画像10枚程度の学習ということを考えると、検出できるだけすごいと考えるべきかも。
関連リンク
- GitHub YOLOv8(YOLOv8の基本的な情報)
- Ultralytics YOLOv8 Doc(YOLOv8の詳細な使い方)
- RectLabel(Mac用アノテーション作成ツール)
- Google Colaboratory(GPUを使って検出やモデルトレーニングができる)
あとがき
YOLOv8を使ってみて感じたのは、つまずくところがなくて、僕のような一般大衆ピーポーでも使いやすいツールに仕上がっていると感じました。
以前のYOLOを使っている方は、移行を検討されてはどうでしょうか?