numpy.partition()関数の使い方が理解できず半日ほど悩んで、よーやく理解できたので共有します。
numpyの公式ドキュメントだけでなく、ググって解説記事などを読んでもなかなか理解できなかった僕が、同じ状況の人が理解できることを意識して解説します。
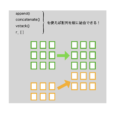
numpy.partition()関数の概念
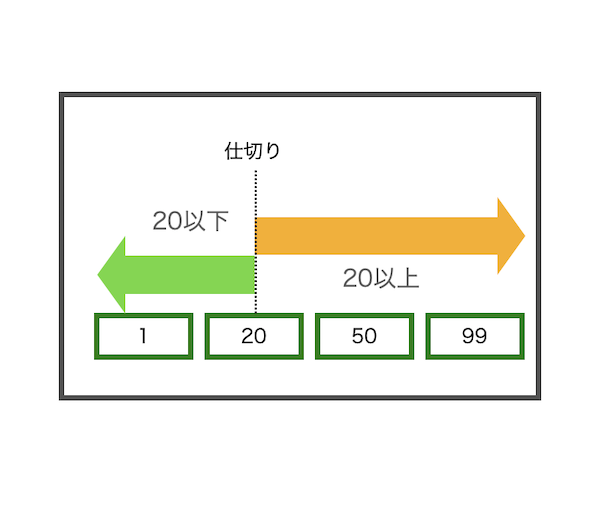
numpy.partition()関数は、値の大きさから見た順番がN番目の要素で内容を仕切ることができます。
numpy.partition(a, kth, axis=-1, kind='introselect', order=None)
概念図:
基本的な使い方
まず基本となる使い方の説明からです。
0〜10までのランダムな数からなる1次元配列(重複なし)について考えます。
a = [ 0, 90, 80, 40, 50, 60, 30, 70, 10, 20]
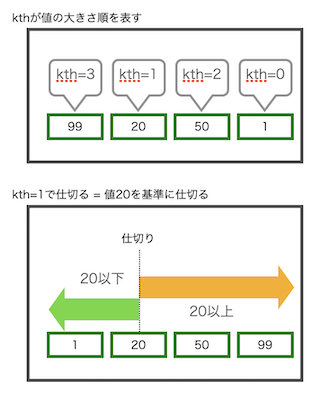
このランダムな配列から、値の大きさが最初のものから2番目の要素で仕切りたい場合、numpy.partition()関数を使って次のように書くことができます。
import numpy as np
parted = np.partition(a, kth=1) # kthは0インデックス
#partedの値 => [ 0, 10, 80, 40, 50, 60, 30, 70, 90, 20]
値の大きさが最小のものから2番目の数字は10なので、10を仕切りとして小さい要素が左側、大きい要素は右側に移動しました。
注意しておきたいのは、結果の内容はソートされているわけではない、ということです。仕切りの数字である10に対して、それぞれの要素が左側に属するか右側に属するかが決定された、というだけです。なので10で仕切った右側の数字は[80, 40, 50, 60, 30, 70, 90, 20]といったように、順番は不規則な状態です。
もし順番どおりに並んでほしいなら単純にnumpy.sort()関数を使いましょう。
それと、kth引数にマイナスの数値を指定すると、値の大きさが最大のものからN番目の値で仕切ることもできます。
parted = np.partition(a, kth=-1)
#partedの値 => [10, 0, 20, 30, 70, 50, 60, 40, 80, 90]
2次元配列に対しての挙動
2次元配列に対してのnumpy.partition()関数を実行すると、1次元配列のときと同じように、純粋に値の大きさがN番目のもので仕切られます。このとき、配列内の行や列の垣根を越えて値の移動が発生する点に注意です。
言葉で説明するのはなかなか難しそうなので、コードサンプルを紹介します。
まず、np.partition()関数の結果が観測しやすそうな配列を作ります。それぞれ縦方向にはランダムで一意な値が入る2次元配列dを作りました。
d = [[ 4, 110, 6],
[ 8, 180, 2],
[ 2, 170, 8],
[ 5, 150, 0],
[ 6, 160, 7],
[ 3, 100, 9],
[ 0, 120, 4],
[ 9, 140, 3],
[ 1, 130, 1],
[ 7, 190, 5]]
これに対してnumpy.partition()関数をかけてみると、結果は純粋に行方向や列方向で値を比較した結果が返ってきます。
p_ax0 = np.partition(d, kth=2, axis=0)
p_ax0の結果:
[[ 0, 100, 0],
[ 1, 110, 1],
[ 2, 120, 2], # ここがkth=2のライン
[ 5, 150, 6],
[ 6, 160, 7],
[ 3, 180, 9],
[ 4, 170, 4],
[ 9, 140, 3],
[ 8, 130, 8],
[ 7, 190, 5]]
p_ax1 = np.partition(d, kth=1, axis=1)
p_ax1の結果:
kth=1のライン
↓
[[ 4, 6, 110],
[ 2, 8, 180],
[ 2, 8, 170],
[ 0, 5, 150],
[ 6, 7, 160],
[ 3, 9, 100],
[ 0, 4, 120],
[ 3, 9, 140],
[ 1, 1, 130],
[ 5, 7, 190]]
純粋なN番目の大きさの値を知りたい場合には効果的ですが、もし行ごとのまとまりが重要なデータに対してはあまり良い挙動ではないですね。この場合、order引数を与えることで、行ごとのまとまりを崩さずにデータを仕切ることができます。
成績上位3名を割り出してみる
ここまでの説明はnumpy.partition()関数がどんな性質のものかを説明するための序章みたいなもの、ここからが具体的に役立つ面白い部分です。
テストの成績表から、上位3名を割り出す、といったことがnumpy.partition()関数で可能になります。
まず、このようなテスト成績表データがあるとします。
data = [
('生徒1', 19),
('生徒2', 47),
('生徒3', 36),
('生徒4', 7),
('生徒5', 74),
('生徒6', 97),
('生徒7', 26),
('生徒8', 51),
('生徒9', 15),
('生徒10', 40),
('生徒11', 85),
('生徒12', 43),
('生徒13', 98),
('生徒14', 39),
('生徒15', 57)]
score_table = np.array(data, dtype=[('name', 'U10'), ('score', 'i1')])
1列目には'name'というフィールド名を、2列目には'score'というフィールド名を付けておきます。
この成績表から、score上位の3名を選出したい場合、次のように求めることができます。
part = np.partition(score_table, kth=-3, order='score')
# partの結果 => [('生徒11', 85), ('生徒6', 97), ('生徒13', 98)],
# dtype=[('name', '<U10'), ('score', 'i1')]
leaders = part[-3:]['name']
# leadersの結果 => ['生徒11', '生徒6', '生徒13']
name列とscore列の関係が崩れていないからこそ、scoreの情報からnameの情報を得ることができます。
成績上位3名・下位3名・その他に分けてみる
それでは、もう一歩推し進めた実用例を考えてみましょう。今度は、下位3名と、上位3名、それに残りのグループに分けてみます。
kth引数は複数の値を指定することができるので、kth=(2, -3)のようにすることで、下位3名と上位3名を境目として仕切ることができます。
part = np.partition(score_table, kth=(2,-3), order='score')
#下位3名
part[:3] # => [('生徒4', 7), ('生徒9', 15), ('生徒1', 19)]
#上位3名
part[-3:] # => [('生徒11', 85), ('生徒6', 97), ('生徒13', 98)]
#その他
part[3:-3] # => [('生徒7', 26), ('生徒3', 36),
# ('生徒14', 39), ('生徒10', 40), ('生徒12', 43),
# ('生徒2', 47), ('生徒8', 51), ('生徒15', 57), ('生徒5', 74)]
同じ得点が4人いた場合は?
ここまで使ってきたデータは値が重複しないものでしたが、データが重複する場合は重大な問題になることがあります。同じ特典が複数人いるような場合です。
例えば上述したような方法で高得点上位3人だけを表彰しようとすると、例えば100点の生徒が4人いた場合、1人は選定から漏れてしまうことになります。
data = [
('生徒1', 40),
('生徒2', 50),
('生徒3', 90),
('生徒4', 91),
('生徒5', 91),
('生徒6', 92), # ←kth=-3で仕切る対象は92
('生徒7', 92),
('生徒8', 95),
('生徒9', 95),
('生徒10', 95),
('生徒11', 95),
('生徒12', 100),
('生徒13', 100),
('生徒14', 100),
('生徒15', 100)]
score_table = np.array(data, dtype=[('name', 'U10'), ('score', 'i1')])
part = np.partition(score_table, kth=-3, order='score')
part[-3:] # => [('生徒13', 100), ('生徒14', 100), ('生徒15', 100)]
# 生徒12から猛抗議を受けることになる
このように、値の重複がある場合には問題になるので注意が必要です。